CAF Performance Specifications Using Benchmarks
Once we completed support for core CAF language features in our prototype CAF compiler, we undertook a study of several of the NAS parallel benchmarks to understand the interplay of CAF language, compiler, and runtime issues and their impact on the programmability, scalability, performance and performance portability of applications. From our colleagues Bob Numrich at University of Minnesota and Allan Wallcraft at Naval Research Lab, we received draft CAF versions of the MG, CG, SP, and BT NAS parallel benchmarks that they created from the MPI codes in the NPB version 2.3 re-lease. Analyzing variants of these codes gave us a better understanding of how to develop high performance programs in CAF. All of the CAF code transformations we describe in this section represent manual source-level tuning we applied to CAF sources for the NAS benchmarks to best exploit CAF language features for performance. It is our goal to enhance the capabilities of our prototype CAF compiler to apply such transformations automatically. Our aim is to generate high-performance code that meets or exceeds the performance of hand-coded MPI parallelizations from easy to write CAF source programs. We are in the process of adding program analysis to our compiler to support automating such transformations.
Performance specifications were measured across the following NAS parallel benchmarks and can be reviewed below.
CG | MG | SP and BT
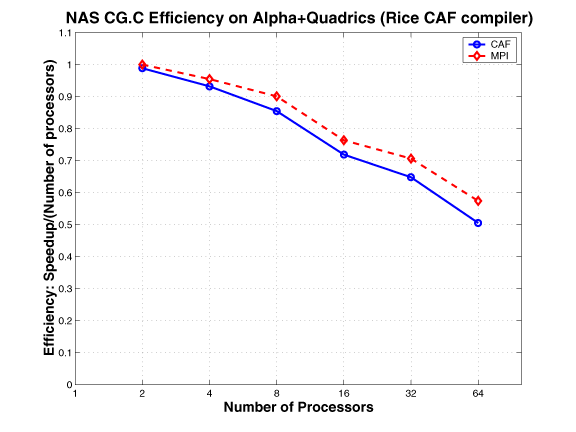
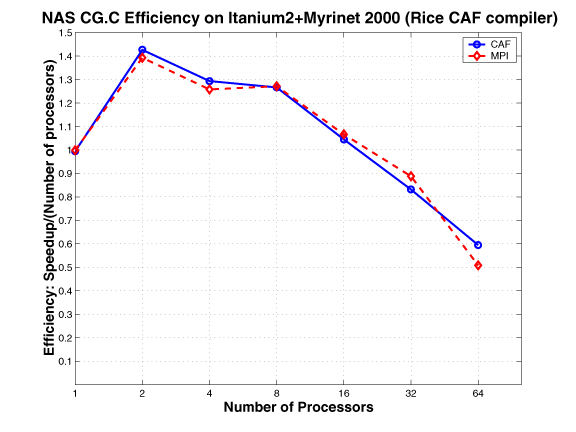
CG
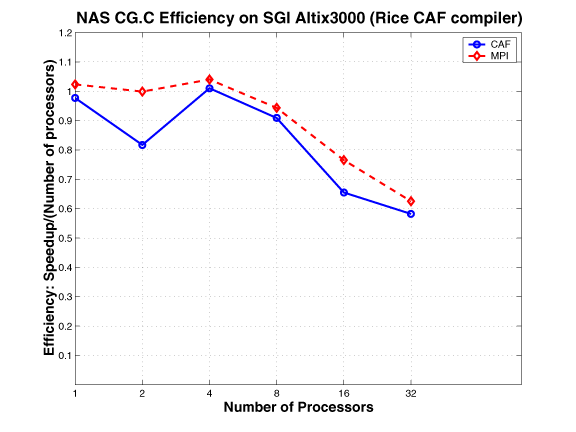
In the NAS CG parallel benchmark, a conjugate gradient method is used to compute an approximation to the smallest eigen value of a large, sparse, symmetric positive definite matrix. This kernel is typical of unstructured grid computations in that it tests irregular long distance communication and employs sparse matrix vector multiplication. The irregular communication requirement of this benchmark is evidently a challenge for all systems.
NAS MG
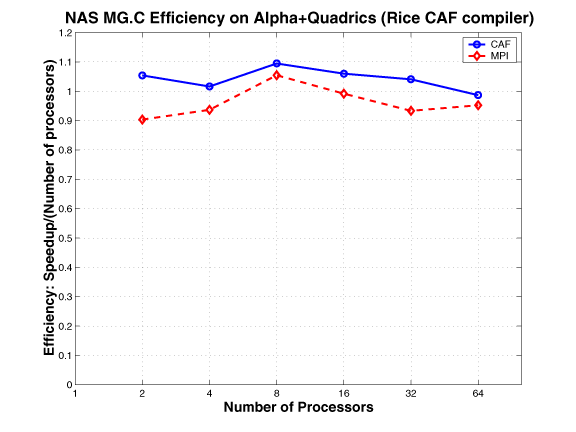
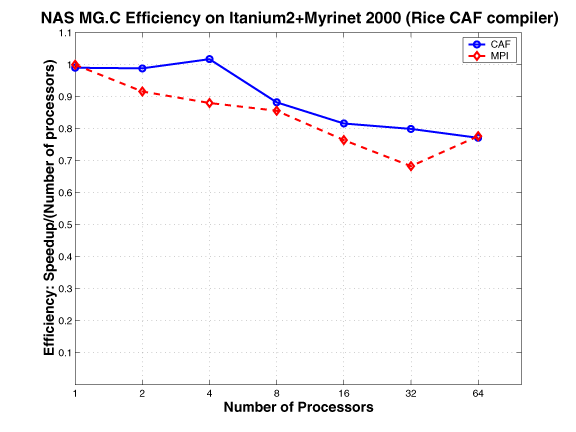
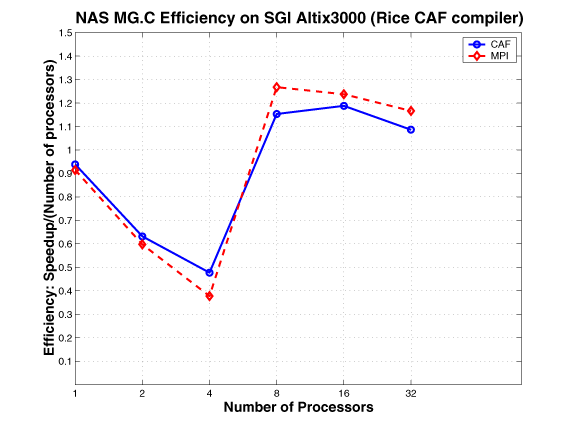
The MG multigrid kernel calculates an approximate solution to the discrete Poisson problem using four iterations of the V-cycle multigrid algorithm on an * n * n grid with periodic boundary conditions. The communication is highly structured and goes through a fixed sequence of regular patterns. In the NAS MG benchmark, for each level of the grid, there are periodic updates of the border region of a three-dimensional rectangular data volume from neighboring processors in each of six spatial directions. Four buffers are used: two as receive buffers and two as send buffers. For each of the three spatial axes, two messages (except forthe corner cases) are sent using basic MPI send to update the border regions on the left and right neighbors. Therefore, two buffers are used for each direction, one buffer to store data to be sent and the other to receive the data from the corresponding neighbor. Because two-sided communication is used, there is implicit two-way point-to-point synchronization between each pair of neighbors.
The CAF version of MG mimics the MPI version. The communication buffers used in the MPI version are replaced by co-arrays; the communication is expressed using CAF syntax, as opposed to using MPI primitives. This approach requires explicit synchronization.
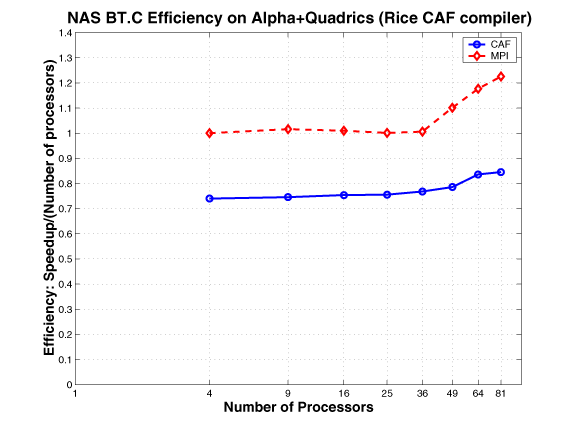
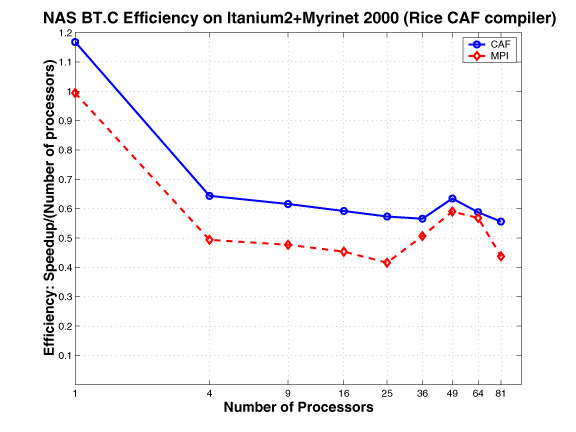
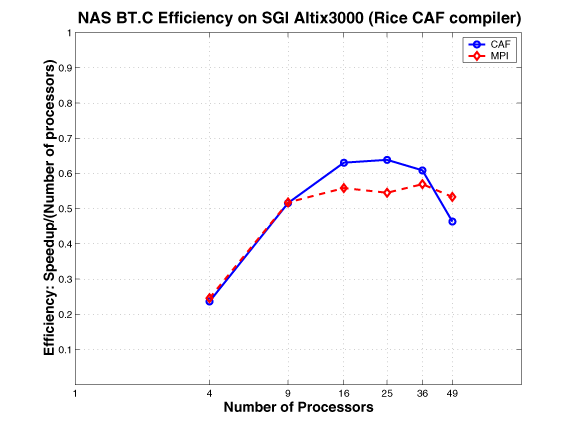
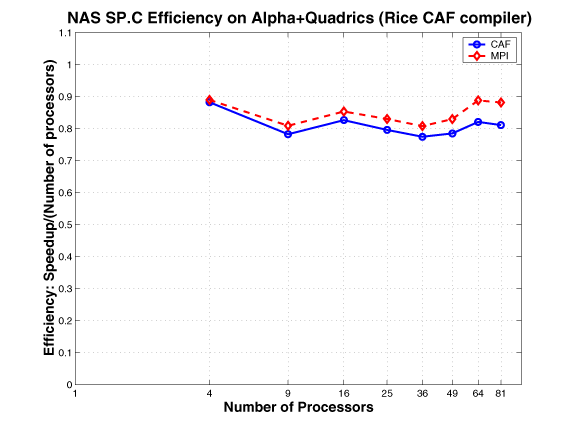
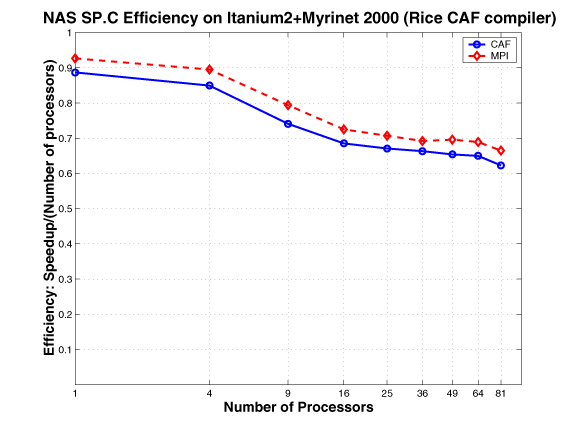
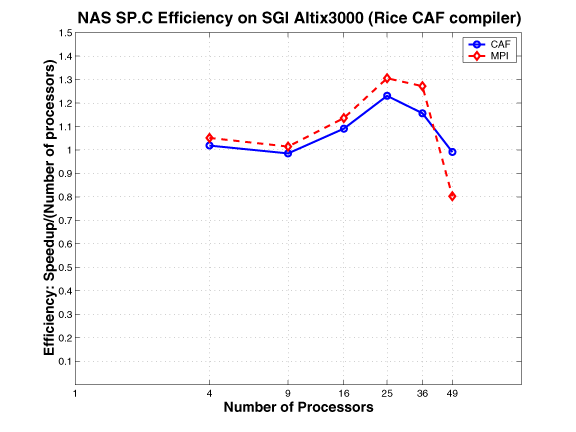
NAS SP and BT
As described in a NASA Ames technical report, the NAS benchmarks BT and SPare two simulated CFD applications that solve systems of equations resulting from an approximately factored implicit finite-difference discretization of three-dimensional Navier-Stokes equations. The principal difference between the codes is that BT solves block-tridiagonal systems of 5x5 blocks, whereas SP solves scalar penta-diagonal systems resulting from full diagonalization of the approximately factored scheme. Both consist of an initialization phase followed by iterative computations over time steps. In each time step, boundary conditions are first calculated. Then the right hand sides of the equations are calculated. Next, banded systems are solved in three computationally intensive bidirectional sweeps along each of the x, y, and z directions. Finally, flow variables are updated. During each timestep, loosely synchronous communication is required before the boundary computation, and tightly-coupled communication is required during the forward and backward line sweeps along each dimension.