A Program-level GrADS approach to using the Grid
Mark Mazina, Rice University, with Holly Dail, Otto Sievert, & Graziano Obertelli of UCSD and John Mellor-Crummey of Rice.
November 8, 2000; revision 0.1 November 13, 2000
Earlier source documents:
- August 6, 2000 Compiler/Resource Selector Interaction Scenario by
Dail, Sievert, & Obertelli.
- August 24, 2000 version of this document by Mazina.
This document proposes an alternative to the library-managed grid invocation
approach of the first demo. Cooperative code development has been ongoing
for about a month on this alternative, but at a lower priority than demo one
work.
We believe there is flexibility in the
program-level approach to encapsulate the library-level approach while
sparing grid-aware library writers from much "glue-it-together" work by
providing standard object interfaces and default object instantiations.
Besides reducing work for the library writers, we hope to address the
following issues:
- Compile/distribute activity should be both automated and "lazy" where
possible - build specific executables when first needed and then store
them in repositories. This does create new issues as to whether a
given user wants to allow the time to create executables in order to
get a larger potential resource space.
- In general, we need to accommodate libraries AND source code,
with probably differing levels of grid awareness. We need flexibility
to address multiple and/or alternative interaction methods.
- The best resource selector will use both application
and environment characteristics. Any selection mechanism
that uses only one could produce poor results.
So resource selection is a difficult problem. It is in some sense
"chicken-and-egg" because to select optimal resources you need
an accurate performance model, yet an accurate performance model
cannot be created until the resources are at least partially known.
Thus we have an exercise in refinement: each stage must
pare the candidate set of resources until a manageable set is
obtained. In general the number and dynamism of grid resources
prevents the gathering of accurate information for all resources in
any practical finite time. It is likely, for example, that we will
not be able to request immediate information on all of the machines
in our GrADS macro testbed in under several minutes. For example,
for 25 machines we are talking more than 1000 measurements just to
get bandwidth and latency.
- An object oriented design methodology is the first step towards
a distributed design. It also allows easier addition of new
techniques and features, such as dynamic contract re-negotiation and
more software-controlled program preparation work.
This description of the program-level approach is weak on the
actual contract binding and runtime monitoring phases - now that we
feel we have some understanding of how to get *to* the contract binding
phase, I plead for help from the experts (or future experts) in that area.
All comments / suggestions will be greatly appreciated.
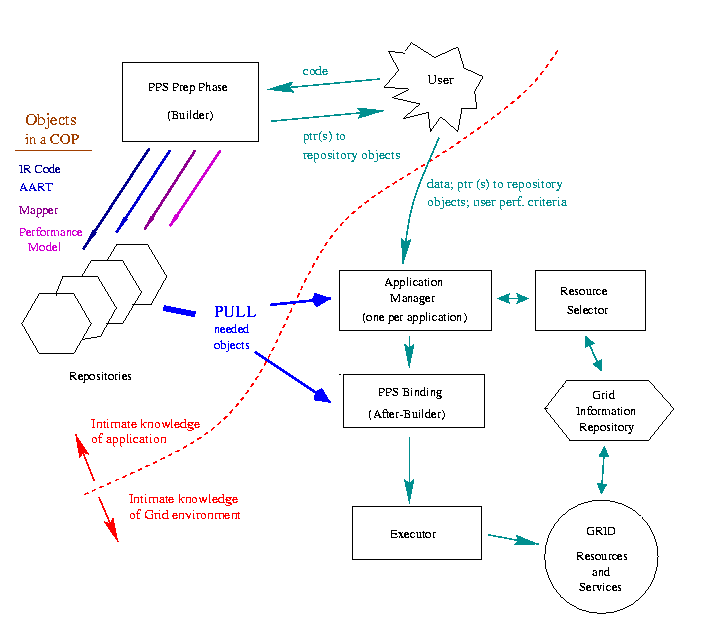
Definitions:
- application -- code implementing one or more algorithms plus a
set of input data; so we know the "problem" size. The term "problem"
refers informally to the data and it's structure as defined by the code.
- application abstract resource topology (AART) --
A description of a class of input-data-independent virtual topologies the
application considers necessary for efficiency. This class description
includes desired characteristics of resources within those topologies.
For now, we plan on using simple, single topology choices such as
N-dimensional mesh, M-way trees of N levels, and fully-connected
graphs.
- virtual machine -- A set of resources with a topology that
maps to the AART, plus expected characteristics
of the resources.
The functionality / services provided by each component:
- PPS Prep Phase (aka the Builder)
- The builder should process the code infrequently, much in the way
we think of current compilers behaving. Some day in the future, the
common case will be the builder just returning pointers to
existing repository objects. Until then, the builder will do most or all
all the following:
- Generates an intermediate representation (IR) of the application
code (e.g. the IR Code Object).
- Creates AART Object (i.e. a resource selection model).
- Creates Mapper Object.
- Creates Performance Model Object.
All four of the above objects collectively make up the
Configurable Object Program (COP)
- Note that the COP itself is a short-lived object, but the (sub)objects
that make up a COP will have shelf life in one or more repositories.
- IR Code Object
- Contains an intermediate representation (IR) of user's code plus
linked-in intermediate representations of library routines or stubs,
including Autopilot-based performance instrumentation. Any high level
optimization efforts during the Binding Phase will use this
intermediate representation.
- AART (Application Abstract Resource Topology) Object
- Describes desired virtual topology w/ topology specific characteristics
(i.e. mesh topology, 2-D, roughly square, balanced communications down
columns).
- Describes the application characteristics using metrics
(discrete values and functions) that are particularly useful for
resource selection (e.g. minimum memory required,
computation / communication balance, performance/processor speedup curves).
- For major library calls, uses, when one exists, an
Abstract Resource Topology specification developed by the library writers.
Such a specification would be stored with other library pieces in the
appropriate repository. A default model, likely built
during GrADSizing a previously Grid-naive library, will be used otherwise.
[Yes, I'm using "Abstract Resource Topology" and "model" interchangeably in
this section.]
- For user code segments, uses a user-provided model
if the user desires (Cactus may) or generates a model "automatically".
Currently, generated models will be simplistic (e.g. crude).
- The complete AART Object will reflect a composition
of the various library call and user code segment models. Actual
composition of the sub-models is an open research issue.
- Should the library writer or user want to do dynamic restructuring
of the run environment, multiple model objects can be created, and the
application divided into run phases. Dynamic
restructuring due to performance remains an open research issue; for now,
fail-restart is expected.
- Mapper Object
- Full instantiation deferred until resource selection is complete;
this object will initially consist of methods to build the
mapper given an AART object.
- Does actual data layout for the virtual machine.
- Performance Model Object
- Full instantiation deferred until resource selection is complete;
this object will initially consist of methods to build the
model given an AART object.
- Once fully instantiated, the Performance Model Object will be
used to:
- Verify original performance criteria can be met.
- Provide the runtime performance monitoring system both
application metrics and resource metrics to measure against.
- Provide the runtime performance monitoring system a way to
provide feedback to the PPS as to the accuracy of the various models
(Resource Selection/Mapper/Performance). If the PPS wants to know
about some behavior for validation of it's components, it must include
both the code to acquire the data and places in the
Performance Model Object for said data to be stored.
- Application Manager
- Coordinates activities of components by storing and passing
around pointers to objects.
- May be specializable for each application. This allows
the data and control flow to be adapted to the application of interest.
Hence each running application has an Application Manager. The issue
of whether multiple Application Managers cooperate is an open research
issue.
- Resource Selector
- Collects info on current Grid environment from Grid Information
Repository
- Uses the AART Object (expanded with information on input-data)
for selection criteria, i.e. what virtual topology do we want?
- Returns a proposed virtual machine (structure based on
topology requested) and a suggested load-balanced work-allocation
based solely on amount of work. The Mapper is responsible for actual
data layout.
- Returns or provides query methods for resource
load, communication link performance, confidence values, and
expected stability of these values over time for the proposed
virtual machine.
- PPS Binding Phase (aka After-Builder, dynamic optimizer)
- Invokes Mapper to develop code for actual data layout,
i.e. the exact block cyclic distribution for LU.
- Chooses appropriate communication mechanism(s) i.e. can we use
multicast effectively?
- Optimizes code for chosen distribution, architecture,
communication mechanism, etc and completes final build.
- Does final instantiation of Performance Model Object.
- Grid Information Repository
- Holds information about the Grid environment.
- Holds pointers to the pieces of the COP.
- Executor (Big Opaque Box to me at this time)
- Does contract binding.
- Loads and starts code on virtual machine. I assume the code loads the
application data.
- Monitors performance, measuring against the Performance Model,
records data on actual behavior.
- At end of application, releases resources and stores
"completed" Performance Model in a repository for off-line PPS analysis.
- Grid Resources and Services
- Initialize, Communicate, (Crunch, Communicate)+, Communicate
How does this compare to the July 2000 diagram developed at
the ANL workshop?.
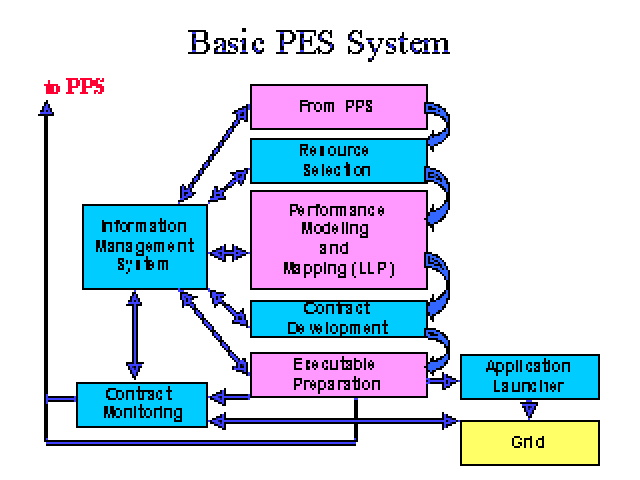
This paper addresses an overlapping view of the GrADS universe as compared
to the above diagram that came out of the July workshop at ANL (aka Fran's
diagram). First, the July diagram is more a high-level partitioning of
the universe into logical blocks of responsibilites; while we focus more
on object interactions just above the actual API level.
We don't have the expertise to address in any significant way
- Contract Development
- Contract Monitoring
- Application Launching
The upper left intimate knowledge of application area on our
diagram fills out the "mist" of what the PPS is doing in the ANL diagram.
We also consolidated the Performance Modeling and Mapping and
the Executable Preparation functionality into a single PPS binding
phase. This doesn't address how Contract Development interacts
with the binding phase as already noted.
Our design adds an Application Manager which can be thought of
as sitting between all the other components, coordinating information
flow. While we show objects in the COP as being pulled directly out of
repositories by the Application Manager and the binding phase,
in practice, we expect the Information Management System will provide
pointers or handles for retrieval of repository objects.
A very brief scenario.
Our User provides the Builder with source code (may be annotated with
resource selection or performance behavior information) *or* a handle
to an existing IR code object previously created for the user.
The Builder constructs any required objects and returns a handle to the COP.
Recall the COP includes the IR Code Object,
AART (resource selection) Object,
Mapper Object, and the
Performance Model Object.
The User starts the Application Manager. This may be the standard GrADS
Application Manager or a user designed one. The Application Manager
needs to be passed the handle to the COP, I/O location information,
the problem size information (specifically, information to allow
calculation of memory requirements), plus any desired performance metrics,
such as completion time.
The Application Manager uses the handle to the COP to retrieve
the AART via a pointer, uses it (the AART) plus
information about the actual data size to query the
Resource Selector.
The Resource Selector takes the incoming model, plus information
about the state of the Grid resources, and develops a proposed
virtual machine with a topology that maps onto the
topology described by the AART.
The Application Manager then calls the PPS Binding Phase, passing it
the COP handle and the user's run-time information.
The PPS Binding Phase invokes the Mapper object to develop IR code for
actual data layout, does final instantiation of the Performance Model Object
and creates optimized binaries. For some Grid-aware libraries, it may
need to arrange for dynamic linking to pre-built libraries for
specific platforms. As early in it's effort as possible, the Binding Phase
should verify the performance objectives can be met assuming model correctness.
Fail-restart occurs by notification to the Application Manager that
some objective can not be met based on the model.
The Application Manager, assuming we are not re-starting, then
passes pointers to the Performance Model object and the binaries to the
Executor. I assume the binaries know where the input data is and
where the output is to go; the Executor should not need to be concerned
with that piece. Recall that at this point, baring dynamic re-configuration
due to poor performance, our topology is known. Even with dynamic
re-configuration, it seems more appropriate to make it the executable's
task to get input - perhaps by first getting a handle from the
Grid Information Repository as to where the data is now.
Then BOB finishes everything (recall Big Opaque Box described above) Fail-restart
should NOT discard the Performance Model object, off-line analysis will be desired.
Back to GrADS